Concepts
Concepts
Machine Learning
Deep Learning
Neural Networks
NLP
Deep Learning
Neural Networks
NLP
Machine learning
Dominant approach:

History
1943: Warren McCulloch & Walter Pitts—mathematical model of artificial neuron.
1961: Frank Rosenblatt—perceptron.
1961: Arthur Samuel’s checkers program.
1986: James McClelland, David Rumelhart & PDP Research Group—book: “Parallel Distributed Processing”.
Neurons

Schematic from <a href="https://commons.wikimedia.org/w/index.php?curid=1474927" target="_blank">Dhp1080, Wikipedia</a>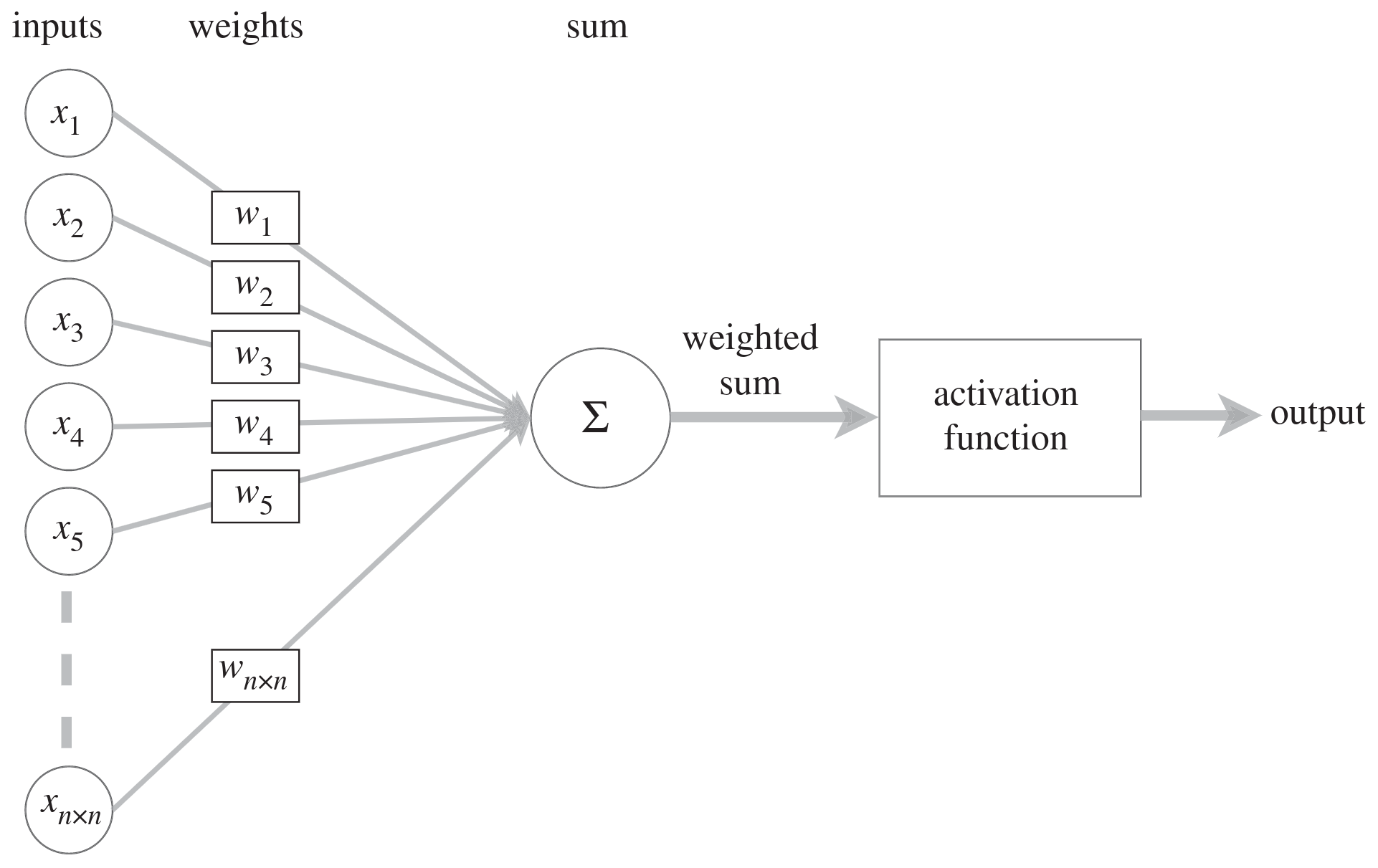
Modified from <a href="https://royalsocietypublishing.org/doi/10.1098/rsta.2019.0163" target="_blank">O.C. Akgun & J. Mei 2019</a>Neural networks
A NN is a parameterized function which can, in theory, solve any problem to any level of accuracy.
The learning process is the mapping of input data to output data (in a training set) through the adjustment of the parameters.
Neural networks

Image by <a href="https://news.berkeley.edu/2020/03/19/high-speed-microscope-captures-fleeting-brain-signals/" target="_blank">Na Ji, UC Berkeley</a>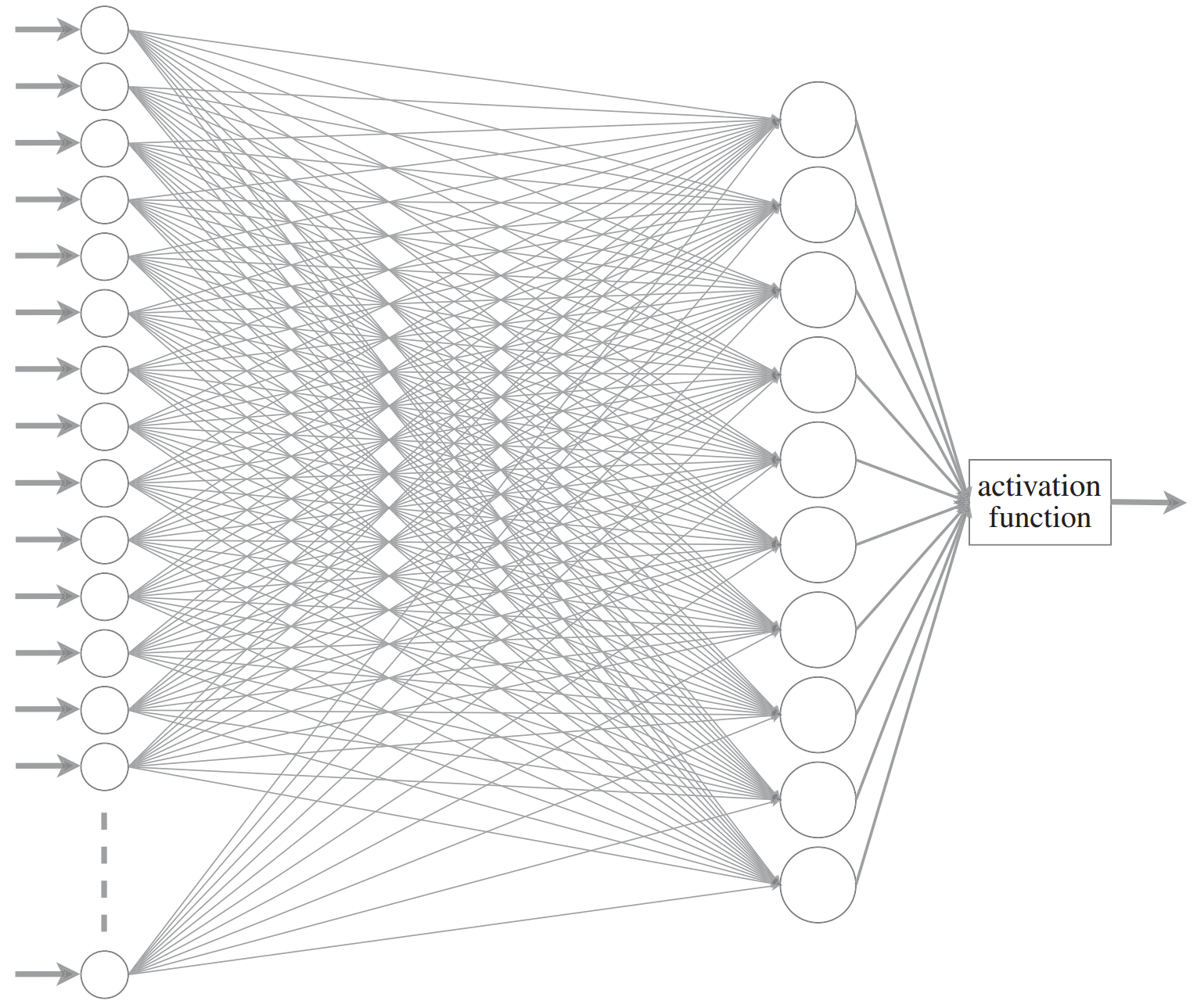
Modified from <a href="https://royalsocietypublishing.org/doi/10.1098/rsta.2019.0163" target="_blank">O.C. Akgun & J. Mei 2019</a>Neural networks
Single layer of artificial neurons → Unable to learn even some of the simple mathematical functions (Marvin Minsky & Seymour Papert).
Two layers → Theoretically can approximate any math model, but in practice very slow.
More layers → Deeper networks
Neural networks
Single layer of artificial neurons → Unable to learn even some of the simple mathematical functions (Marvin Minsky & Seymour Papert).
Two layers → Theoretically can approximate any math model, but in practice very slow.
More layers → Deeper networks → deep learning.
Types of NN
Fully-connected, feedforward, single-layer NN

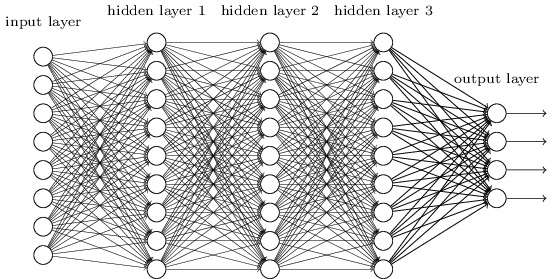
Fully-connected, feedforward, deep NN
Convolutional neural network (CNN)
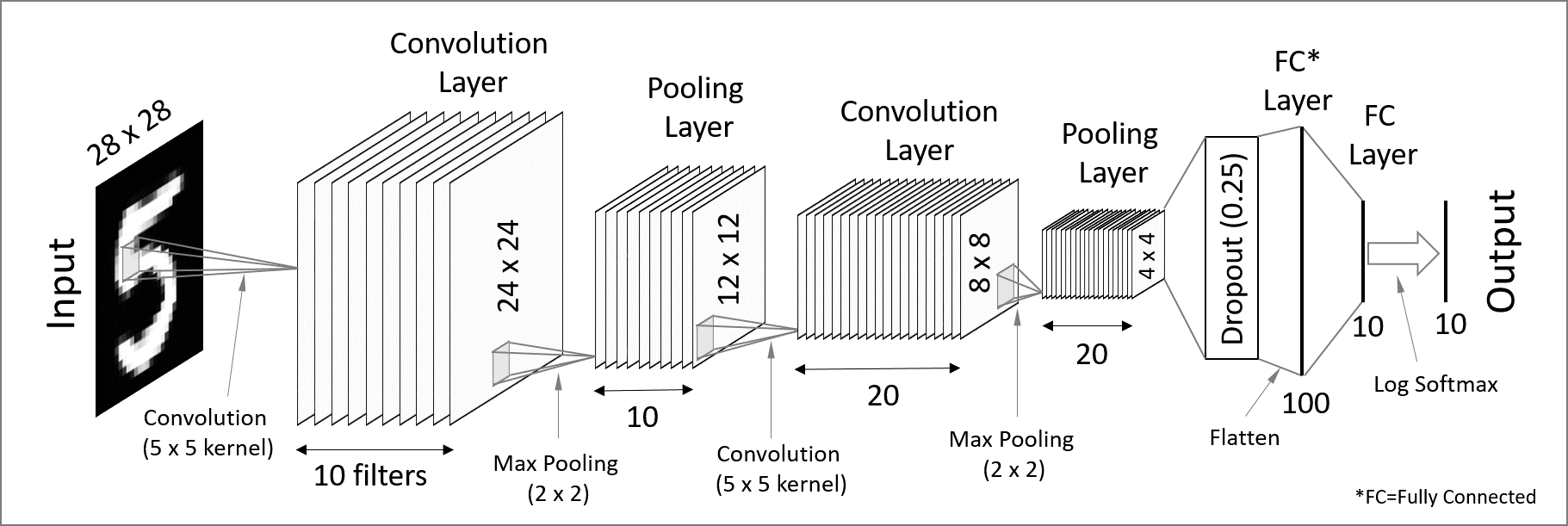
Used for spatially structured data.
Convolution layers → each neuron receives input only from a subarea of the previous layer.
Pooling → combines the outputs of neurons in a subarea to reduce the data dimensions.
Not fully connected.
Recurrent neural network (RNN)

Used for chain structured data (e.g. text).
Not feedforward.
General principles
Building a model
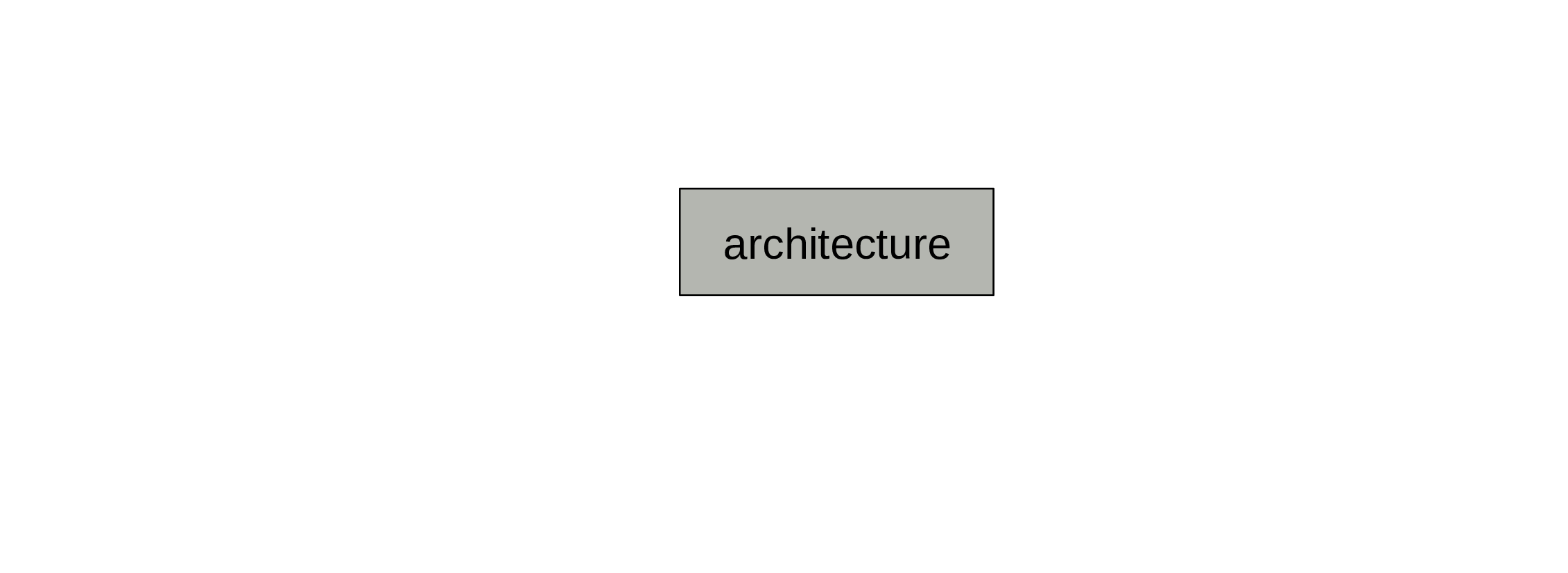
First, we need an architecture (size, depth, types of layers, etc.).
This is set before training and does not change.
Building a model
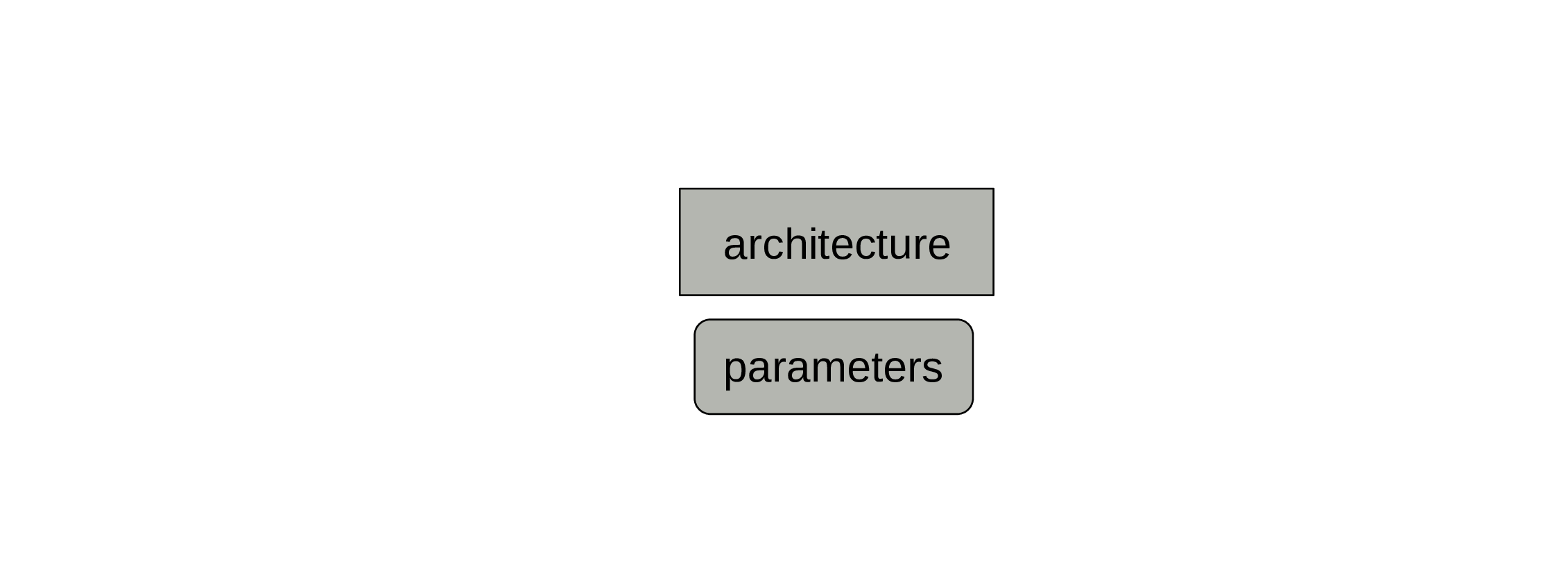
A model also comprises parameters.
Those are set to some initial values, but will change during training.
Training a model

To train the model, we need labelled data in the form of input/output pairs.
Training a model

Inputs and parameters are fed to the architecture.
Training a model

We get predictions as outputs.
Training a model
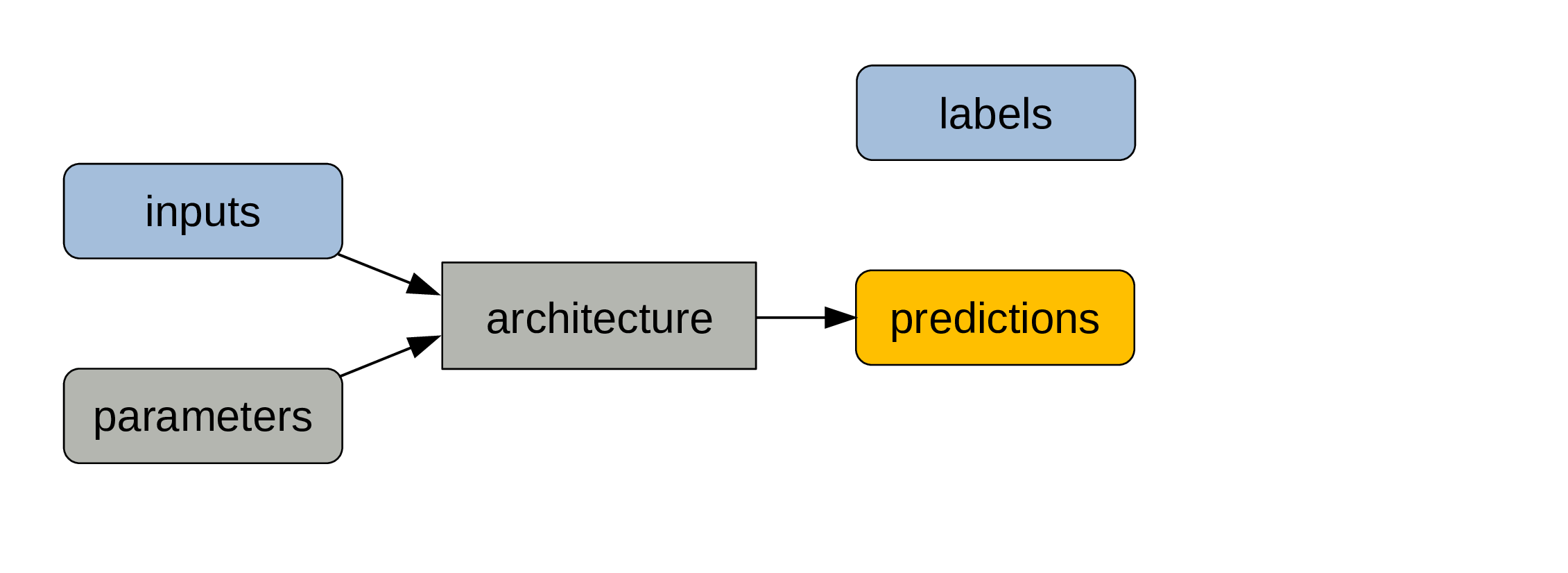
A metric (e.g. error rate) compares predictions and labels and is a measure of model performance.
Training a model
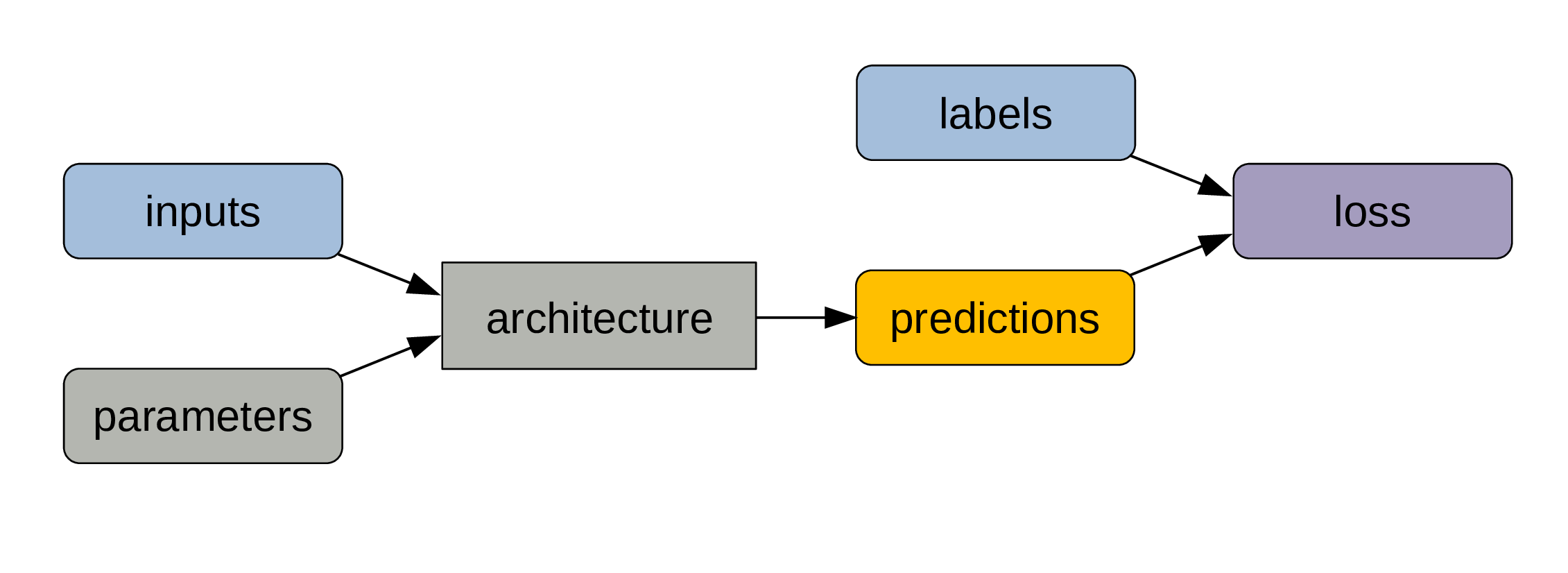
Because it is not always sensitive enough to changes in parameter values, we compute a loss function …
Training a model

… which allows to adjust the parameters slightly through backpropagation.
This cycle gets repeated for a number of steps.
Using a model

At the end of the training process, what matters is the combination of architecture and trained parameters.
Using a model
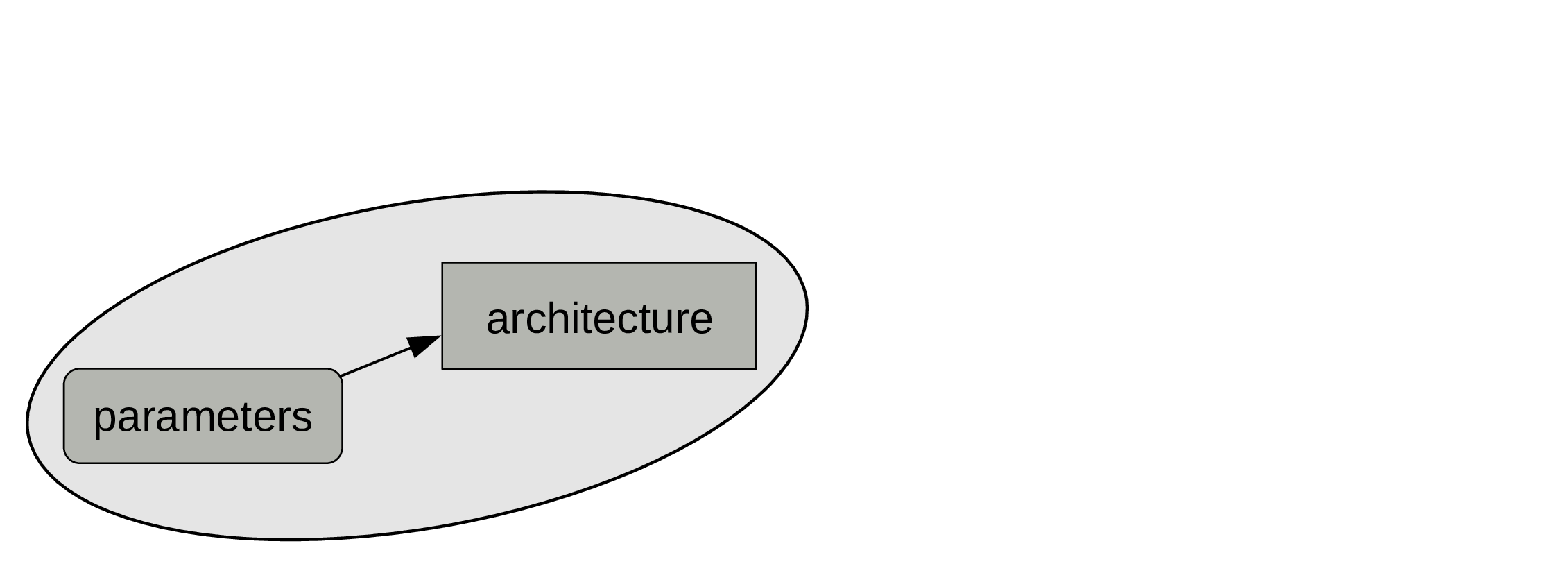
That’s what constitute a model.
Using a model

A model can be considered as a regular program …
Using a model
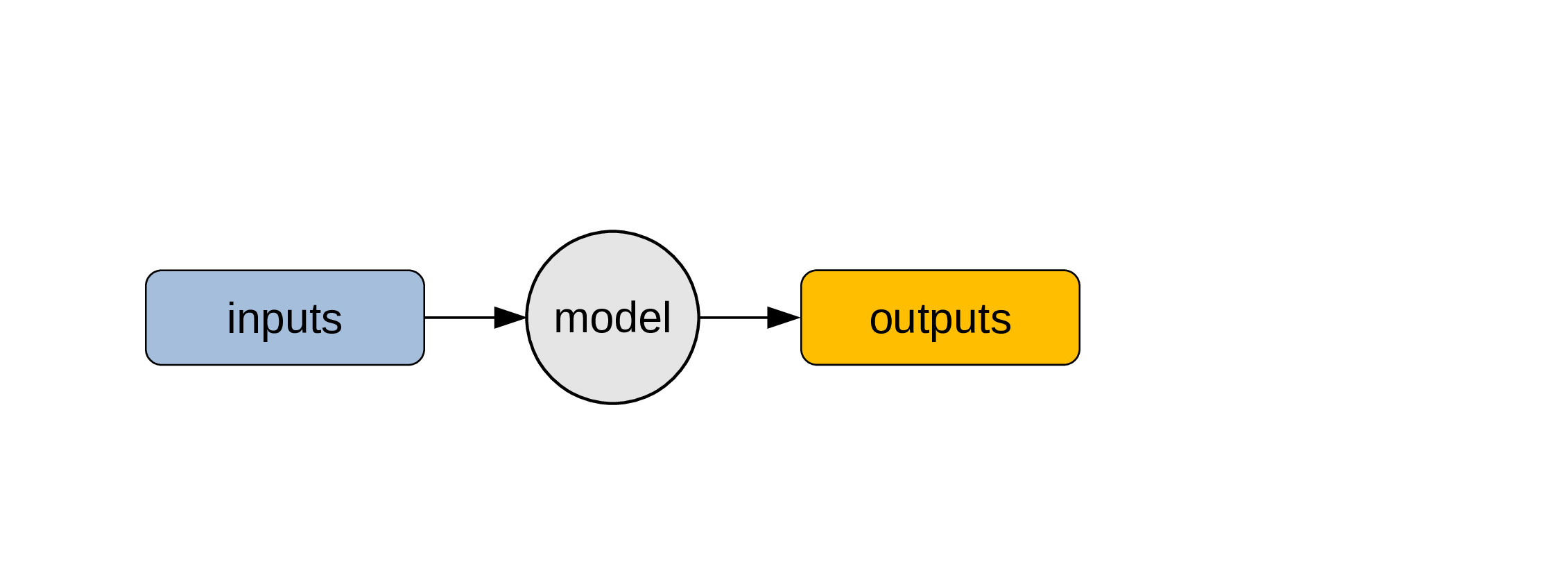
… and be used to obtain outputs from inputs.
Natural Language Processing
Language models
A language model is a probability distribution over sequences of words. It attempts to predict the next word after any sequence of words.
Pre-trained models can be used to quickly get good results in all sorts of problems such as, for instance, sentiment analysis.
Data bias
Bias is always present in data.
Document the limitations and scope of your data as best as possible.
Problems to watch for:
- Out of domain data: data used for training are not relevant to the model application.
- Domain shift: model becoming inadapted as conditions evolve.
- Feedback loop: initial bias exacerbated over the time.
The last one is particularly problematic whenever the model outputs the next round of data based on interactions of the current round of data with the real world.
Solution: ensure there are human circuit breakers and oversight.
Two main types of models
- Classification
- Regression
Major pitfall: over-fitting

Major pitfall: over-fitting
- Training too long
- Training without enough data
- Too many parameters
Transfer learning
Repurposing pretrained models.
- Less data needed
- Less computing time needed
- Leads to better accuracy
fastai
What is fastai?
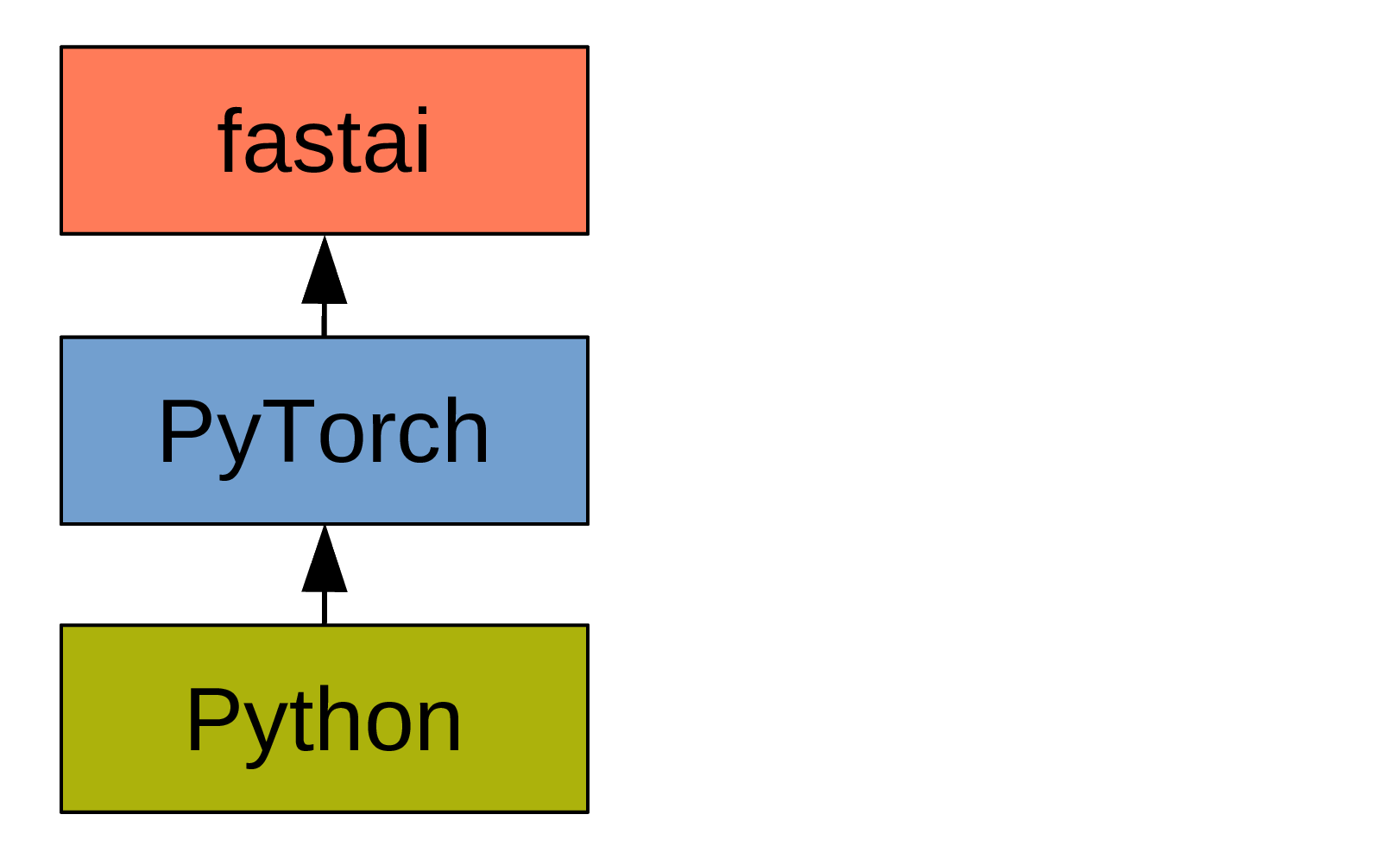
What is fastai?
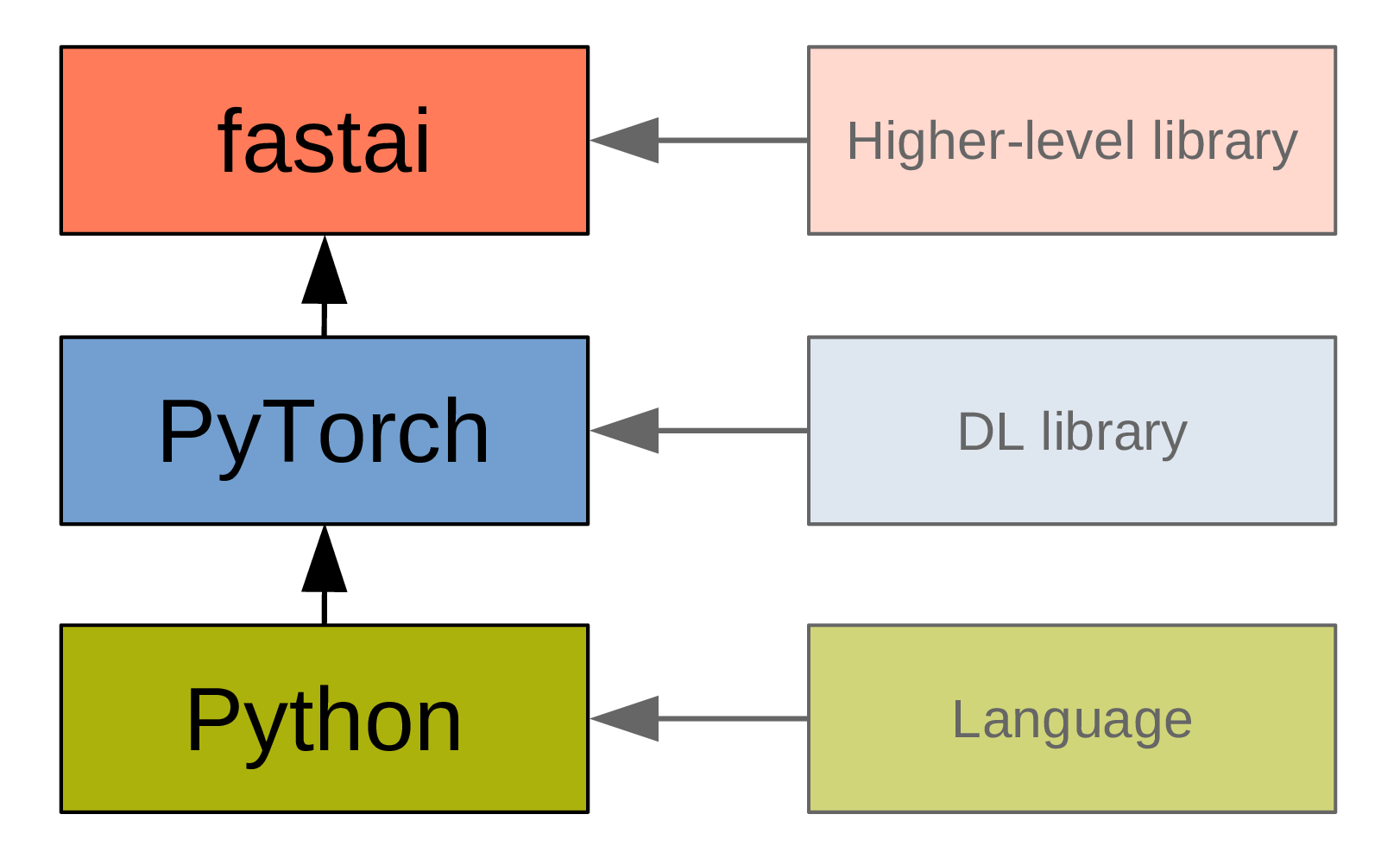
PyTorch

- Very Pythonic.
- Widely used in research.
fastai
fastai
is a deep learning library that builds on top of PyTorch, adding a higher level of functionality.
[It] is organized around two main design goals: to be approachable and rapidly productive, while also being deeply hackable and configurable.
Resources
Documentation
Manual
Tutorials
Peer-reviewed paper
Book
Paperback version
Free MOOC version of part 1 of the book
Jupyter notebooks version of the book
Getting help
Basic workflow
- DataLoaders
Create iterators with the training and validation data.
- Learner
Train the model.
- Predict or visualize
Get predictions from our model.